This article is particularly aimed at Data and Analytics functions in large organizations. I'm confident that some of the observations will hold true for smaller organizations, but they ultimately come from observing the behaviors, and processes at large companies. In particular I am drawing on experience working at organizations that have vey separate "Analytical" and "Data Engineering" teams. I believe that this is common at large scale companies. If your organization doesn't completely match this, then some of the issues I highlight may seem strange to you, but there may still be some ideas you can take away.
"Data Driven" has become an increasing popular phrase, and many organizations genuinely attempt to run efficiently and effectively based on analyzing their data. In my experience however, this doesn't stop the evolution of some convoluted and bureaucratic processes in this area. This is my attempt to highlight some of the common "anti-patterns", and suggest some straightforward alternatives - influenced by my experience running software development teams.
The following diagram shows a typical flow of data through to a usable end product. There are variations, but these tend to be a result of a particular technical implementation , or simply has a reduced scale in one or more areas. E.g. a smaller company may not have a rigorous process for validating and approving reporting output - but a government organization certainly will.
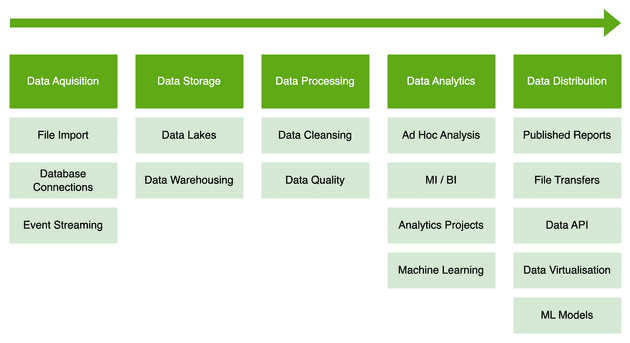
Data flows from left-to-right, from initial data capture to the eventual "distribution" of reports and data files. The term "distribution" isn't commonly used in this space, but I think it neatly captures the nature of what happens at the end of an analytics project.
First data has to be acquired. Then there can be considerable variety in how the data is consolidated, cleaned and made available for Analytics teams. Analytics itself can involve complex Python scripts, a propriety tool, the ubiquitous Microsoft Excel or a combination of all 3.
There is typically less variation in report distribution, with Tableau, PowerBI and ClickView dominating the vendor space. File exports for different departments or organizations are alo very common. API's however are disappointingly rare considering how well they fit this space from architectural perspective (Author note to self : Write about Data API's).
So where do the problems start?
The main issues that I have repeatedly observed are driven by two main factors:
- Too Many Hand-offs
- Skills gaps
- Friction over Infrastructure
Too many Hand-Offs
As we can see from the following diagram, a range of different skills are required at different points along the path to a completed project.
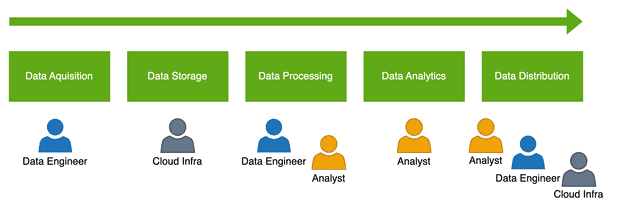
If everything runs smoothly, this shouldn't be a problem. Data Engineers acquire the data, serve it to Analysts, who then complete their work - simple! Sadly this doesn't happen often in reality, and so hand-offs and cross team working becomes increasing necessary. This wouldn't be so harmful if projects followed a repeatable waterfall like process, but data projects are particularly prone to changes, and this can cause the number of hand-offs and cross team interactions to escalate rapidly.
Data projects often have a consistent (positive) work generation property:
- Stakeholder asks for some analysis on Factor X
- Analyst provides the analysis, complete with reports and dashboards
- [Stakeholder] "That's great, but not quite what I expected. Can you drill into Factor Y for me please?"
- [Analyst] "I haven't got the data for that, I'll have to go back to Engineering"
- [Developer] "I'm working on another project now, I'll get to that later"
It's a really good sign when Stakeholders ask for more. it strongly implies that the preceding analysis has value, and has engaged peoples curiosity. What we now need is a quick turn around to maintain momentum, but this can be difficult to achieve when departmental and organizational boundaries stand in the way.
This is why multiple hand-offs are so painful for analytics work. The very nature of the work is flexible and responsive, but all too frequently the teams we build around the work are not.
Hand-off between teams can reduce performance and increase delivery variability. This is aggravated if the different teams have different managers, priorities and objectives. It's always frustrating when you have to wait for work to be completed, particularly when you know that it's a straightforward task, but sat, unloved and uncared for in someone elses backlog. We all encounter it from time to time, but it seems particularly prevalent in the world of data and analytics, and is often the result of poor organizational design, or under-funding in technology areas.
Skills Gaps
The frustration of relying on external teams will naturally push analytical teams to want to do more, control more and own more. This is not in of itself a disastrous conclusion to come to, but it can be difficult to put ito practice effectively because of skills gaps.
Data acquisition typically requires the skill-set of a Data Engineer. It may involve coordinating with other technical teams negotiating user rights to access a production database (or replica), liaising to set up VPN access, and require a reasonable degree of technical know how. It's also likely that the technical tool-set may specific to the data engineering teams, especially if dedicated ETL tools are in use.
The reliance on the Data Engineering skill-set increases as the scale of the data increases.
Required knowledge of CDC (Change Data capture), Event Driven technologies or how to structure data correctly in a Data Lake, become mandatory if the data sizes are large and the data is changing rapidly.
Creating reliable, reusable code to move data in an efficient manner requires an engineering mindset. Standard development practices such as source control, CI/CD and error logging are (should be) the default here.
Whilst Analysts or Data Scientists might not fully appreciate the skills required to become a first class data engineer - the reverse can also be the case. Tech heavy teams can trivialize the expertise of their analytic colleagues, and push for more of the workload to happen towards the beginning of the data lifecycle. The automated, controlled part of the lifecycle. Whilst this may well improve the data processing efficiency, it can prevent analytic expertise (domain knowledge, statistical analysis skills) from being used in an optimal manner.
Areas of Contention
Data quality and data modelling are areas in which I commonly see contention between data engineers and analysts.
This contention typically arises because data quality and data modelling require domain knowledge. Its not always possible for data engineers (especially at large organizations) to be experts in all of the organizational domains. Healthcare is a particularly acute example, because domain knowledge can be highly specialized, with consensus difficult to reach, even with experts assigned to a project. But engineers remain the experts in producing efficient code. Industrial scale analytics can require tens of millions of records to be processed daily, so efficiency and automation are a necessity.
Balancing the need of domain knowledge and efficient coding practices requires collaboration between engineers and analysts. This can be difficult and costly - especially if organizational structure and departmental boundaries impede the process of collaboration.
Conways Law neatly describes why this sort of issue is likely to arise, with Analytics teams separated from Data Engineering by departmental boundaries. This is commonly exaserbated by individual business units demanding their own Analytics Teams.
"Organizations, who design systems, are constrained to produce designs which are copies of the communication structures of these organizations. - Melvin Conway"
Anti-Patterns
I've tried to highlight some of the common areas fof friction between technical and analytical teams. What happens when an organization is biased towards one or the other?
These next diagrams attempt to illustrate what happens when organizations "skew" one way or the other.
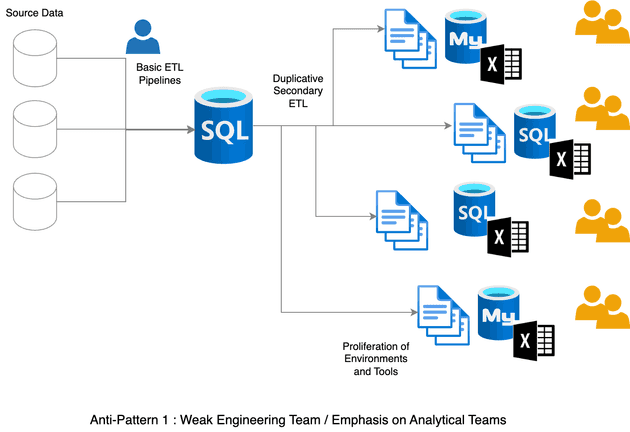
In pattern one, we have an under-developed or under-funded engineering Team. This leads to a proliferation of environments in the analytics area. Likely other side-effects are difficulties maintaining systems, lack of consistent meta data nad data lineage, inconsistent security practices etc.
In the second pattern we have he reverse scenario. There is a high level of automation in the engineering space, which leads to improved logging, meta-data visibility and security practices. But it is highly prone to the frustrating workflow I highlighted earlier. It is common for off-book or "shadow IT" systems to emerge in this scenario, as frustrated Analytic teams attempt to accelerate projects.
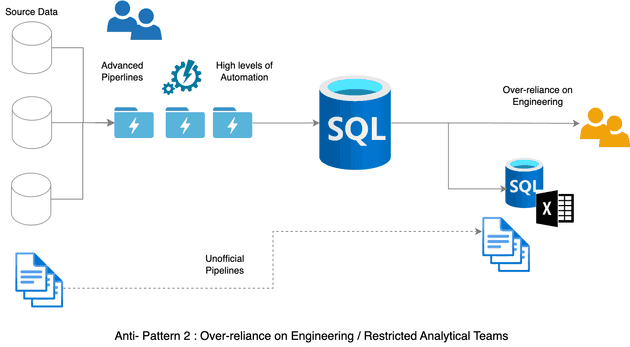
Friction over Infrastructure
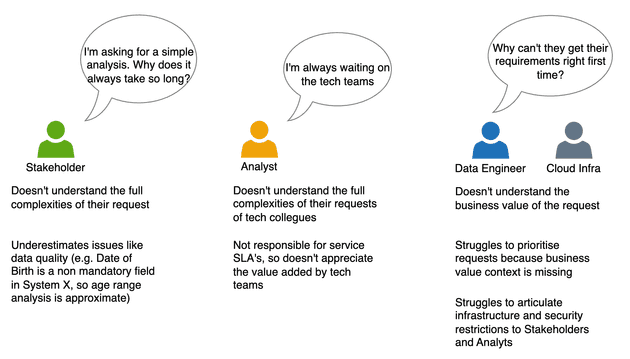
I don't want to simultaneously offend everyone working in Data and Analytics, so the diagram above attempts to highlight the different misunderstandings for different teams. In practice these misunderstandings can generate genuine friction and bad feeling that can require significant effort to mitigate and resolve.
For example - the recent GDPR regulations have certainly increased friction for internal teams over the last few years. The requirement to be transparent over data held and processed increases the demand on IT systems to capture and record data lineage with far more rigour than was previously required. The restrictions on the purpose for holding and processing data are particularly challenging to tackle.
This increase in audit and transparency requirements has happened at the exact same time as the "big data revolution". The promise of mining deeper and more valuable insights from our data while using increasingly powerful tools and techniques is difficult to marry with a world of increasing constraints.
The new world of Cloud Data hasn't just given us amazing new tools and techniques for free. These tools require a significant uplift in technical capabilities in order to utilize them in a compliant manner.
I hear a lot of frustration from Analysts articulated as "Why can't I just....", and I sympathize with them. Why can't IT make things go faster with all of their lovely cloud tools. I also feel for Infrastructure Teams who continually feel like the bad guys.
I like the way Daniel Terhorst-North sums this up.
“Autonomy without alignment is anarchy.
— Daniel Terhorst-North @tastapod@mastodon.social (@tastapod) October 24, 2022
“Alignment without autonomy is autocracy.”
It sometimes feels like a constant battle between the business trying to reach their goals as quickly as possible, and IT trying to keep everyone as safe as possible - with little love lost in between. So how can we fix it?
How do Cross Functional (Agile) Teams fix this?
Its all about misaligned incentives - it always is.
Hopefully my diagram on "common misunderstandings" helps illustrate the biggest impediment to successful collaboration:
- Stakeholders are incentivized to "get results" or obtain data to support their initiatives
- Engineers and Infrastructure teams are incentivized to create robust, secure and auditable systems.
- Analysts "just want to deliver" and can feel sandwiched between Stakeholders and Engineering teams.
This situation isn't unique to Data projects, and the most common solution for this is to create a cross-functional or "Agile" team.
This type of team structure is very well established in the world of software development, and it's slightly strange that it hasn't seen wider adoption in the world of data and analytics. I won't spend long diving into the history of Agile, as that would definitely require a much longer article, but I will highlight the key benefits of adopting such an approach.
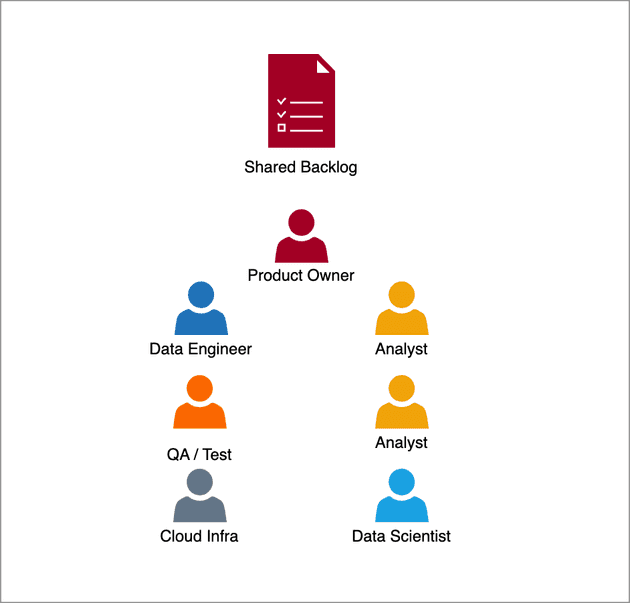
Here we see a typically structured agile team. In this new setup the most obvious advantage is that now...everyone is working together towards a common goal!
It's worth underlining this seemingly simple point.
In this case, obtaining and provisioning data is now everyone's responsibility. But (crucially) the team now contains the necessary resource to make this happen - and make this happen in the most efficient and highest quality way. We immediately remove the cross team or cross department dependencies, and this removes the wasteful and frustrating activity of prioritizing work in other teams backlogs.
A subtler improvement, but one that I have personally observed on many occasions, is that engineering resources now genuinely feel part of the value generation process. Analysts can now contribute to data engineering tasks and vice versa, without anyone feeling that people area "playing on their turf" of overstepping their jurisdiction.
Lets have a look at our original list of misaligned incentives, and see how the new structure addresses them:
- Stakeholders are incentivized to "get results" or obtain data to support their initiatives
- The product owner represents the stakeholders, and now has clear visibility of the task list and progress against it. They have far greater influence on the project resource, and in turn, can provide clear explanations to the team on the rationale for decisions and priority calls.
- Engineers and Infrastructure teams are incentivized to create robust, secure and auditable systems.
- Engineers are now a fundamental part of the team. The need to create robust systems has not disappeared, but they have gained a mechanism with which to communicate their challenges immediately and directly.
- Analysts "just want to deliver" and can feel sandwiched between Stakeholders and Engineering teams.
- Analysts are now part of a bigger, more supportive team. Challenges with delivery are more rapidly understood by the product owner, and more rapidly tackled by the engineers. The new structure also opens up many new avenues for skills acquisition and improvements. This can help close the skills gap, and potentially offer improved or extended career paths to analysts who embrace the new ways of working.
I added "Data Scientists" to the agile team diagram, and I could have easily reframed this article around the similar challenges that Data Scientists encounter in large organizations. Their reliance of large scale datasets and advanced tooling exacerbates the issues highlighted here, and can again be comfortably addressed by adopting a cross functional way of working. Working closely with engineers and analysts is, once again, a great for for Data scientists to widen their skill set. Not by reading textbooks, but by engaging in real world problems, and by getting exposure to tools and techniques used by their new colleagues.
Common Challenges to cross Functional Working
It would be unfair of me to paint agile as a panacea for all of the problems in the world of data and analytics. Moving to a new way of working presents organizational challenges, and attracts an array of issues in the same way as any transformational change. Rather than digress into the complex world of change implementation at large organizations, I'll just highlight the most common challenges.
Being a Product Owner is quite challenging
This new team structure introduces a role that is likely to not have existed before. Should we assign a Project Manager to the role? Or a Business Analyst? Or the Tech Lead?
In reality it can be challenging to identify the right person, and it might take time to identify the ideal candidate. Regardless, they will definitely need support, and that is not always readily available at organizations new to agile processes.
A successful Product Owner needs to represent both the Stakeholders and the Technical teams. Managing this requires skill and is helped greatly by experience, so it's definitely worth investing time and effort into coaching, training, mentoring or any other type of support for people new to the role.
Profession Management vs Project Management
Working as a cross functional team does not mean that Product owners need to take on line management responsibility. In fact this can quickly have negative side effects. Engineers and Analysts are better served by line managers with expertise in those domains, and can find it difficult to improve and develop without them.
In any team it's important that people can speak freely and experience respect for their professional opinions. This is always hampered if reporting lines are involved, as many people will feel disinclined to contradict or vigorously debate their boss.
Adopting cross functional teams may require significant re-wiring of an organization - and this can be extremely difficult. It's certainly a topic far too big for this article - I'll consider sharing some of my experiences in a separate post.
Back to the positive
The organizational challenges of implementing cross functional teams will inevitably vary dependant on the maturity or complexity of the organization. This shouldn't detract for the core ideas however.
If we recap our initial issues, how do cross functional teams help address them?
Too Many Hand-offs
By locating (physically or virtually) the team members together, we immediately see a dramatic improvement in this area. Not just because we minimize the bureaucracy of assigning work to different departments, but also because the team members are now unified behind a common goal. Everyone is being rewarded for the same thing, so prioritisation becomes simpler, and a shared group activity.
Skills Gaps
Skills gaps will still be there, but we are:
- Helping people develop an acquire new skills in an organic manner. Working closely on practical problems is by far the fastest and most effective way to learn, and cross functional teams provide an optimal environment for this to happen.
- Mitigating individual skills gaps by building multi-skilled teams. The issues are now much less relevant because the team has all the skills it needs.
Friction over Infrastructure
Infrastructure are now much more aligned to the work that relies on them. Once again, this can help enormously with productivity, and also the general well being of the team. Infrastructure are no longer the "bad guys". At worst they become "our bad guys"!
Summary
In summary, the move towards cross functional steams for data and analytics can be a natural evolution, or a drastic change to an organization, but hopefully I've illustrated how this approach tackles a number of the most common blockers to progress and productivity.
I've deliberately played down the references to "agile", because I know that this can be off-putting or intimidating for people unfamiliar with software development. But hopefully I've encouraged people to take a look at what have become mature and well developed practices, and see which parts they can use.
I have a separate article on adopting agile - feel free to check that out as well.